Unit Root Test
We’ve been applying different orders of differencing on simulated data by looking at the time series plot and ACF plot. In this chapter, we introduce the Dickey-Fuller unit-root test, or the DF test, that helps us check whether differencing is necessary or not. The test shouldn’t be used as the single source of truth, but rather an addition to the existing plotting methods to decide whether to apply differencing.
Dickey-Fuller test
If $X_t$ is either an AR(1) model or an AR(1) with some mean trend:
$$ X_t = \phi X_{t-1} + Z_t, \quad X_t = \delta + \phi X_{t-1} + Z_t, \quad X_t = \delta_0 + \delta_1 t + \phi X_{t-1} + Z_t, $$
then the null hypothesis of the unit-root test is $H_0: \phi = 1$ (nonstationary)1 and the alternative hypothesis is $H_1: \phi < 1$ (stationary). If we fail to reject $H_0$, then the series might be a random walk and the stochastic trend could be removed by differencing. If we reject the null, then the time series is stationary and no differencing is necessary.
The test statistic is
$$ DF = t\text{-ratio} = \frac{\hat\phi - 1}{se(\hat\phi)} $$
where $\hat\phi$ is the LSE. The p-value could be calculated by a nonstandard asymptotic distribution, which is repeatedly generating data (resampling / bootstrapping) from a random walk to get the distribution of $\hat\phi$. In R,
| |
Augmented DF unit-root test
The DF test has a strong model assumption, and it’s very rare for a real time series to be explained by a random walk. If we observe an increasing pattern in the time series plot, and a slowly decaying pattern in the ACF plot, but the DF test says no differencing is needed, then maybe the data is not generated from the specific model.
The augmented Dickey-Fuller (ADF) test relaxes the assumption to an AR(p) model:
$$ \nabla X_t = c_t + \beta X_{t-1} + \sum_{i=1}^{p-1} \phi_i \nabla X_{t-i} + Z_t $$
The null hypothesis is $H_0: \beta_0$ (nonstationary), and the alternative hypothesis is $H_1: \beta < 0$. Similarly, if we fail to reject the null, then differencing might be necessary. If we reject $H_0$, then the series might be stationary or is an explosive AR2.
In the following section we’re going to see how the ADF test works on different datasets.
| |
By default, the alternative parameter is set as “stationary” in the adf.test() function. With a p-value smaller than 0.01, we reject the null and conclude that the process is stationary. We could also check if the data is an explosive AR:
| |
And clearly it’s not. What if we use this on an actual explosive AR series?
| |
With a p-value smaller than 0.01, we reject the null and conclude that we have a nonstationary explosive AR series.
Over-differencing
Unnecessary differencing can cause artificial autocorrelation and make the model fitting process complicated. For example, suppose $X_t$ is a random walk, then
$$ \nabla X_t = X_t - X_{t-1} = Z_t $$
But what happens after second order differencing?
$$ \nabla^2 X_t = \nabla(Z_t) = Z_t - Z_{t-1} $$
With first order differencing we can simply fit a white noise, but after another round differencing an MA(1) model would be needed. Always keep the principle of parsimony in mind!
Another example with $X_t \sim WN$. With some manipulation,
$$ \begin{gathered} X_t = Z_t, X_{t-1} = Z_{t-1} \\ -0.5 X_{t-1} + 0.5 Z_{t-1} = 0 \\ \Rightarrow X_t = -0.5 X_{t-1} + Z_t + 0.5 Z_{t-1} \end{gathered} $$
The WN could be modeled as an ARMA(1, 1). If we have a choice between the two, WN is preferred by the principle of parsimony.
Model selection
We’ll test what we’ve learnt on removing the mean trend on the Lake Huron dataset, which contains the yearly levels of Lake Huron in the years 1875-1972.
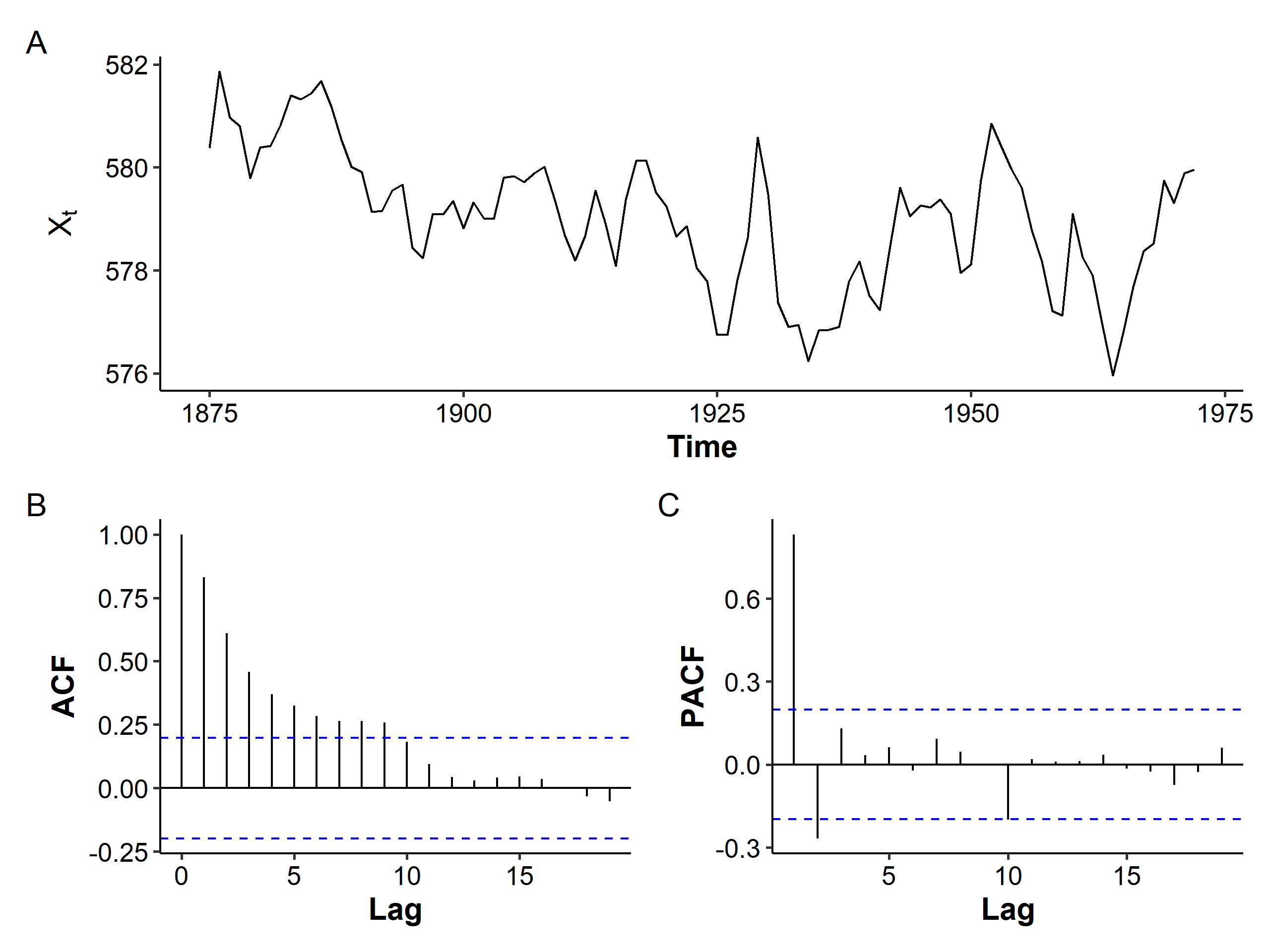
The mean seems to be decreasing over the years, and the variance seems to be slightly increasing. The ACF is more of a tail-off pattern than a slowly decreasing one. If we assume stationarity and fit an AR(2) model with an intercept:
| |
Of course we could also assume nonstationarity and fit ARIMA models of different orders. So how do we choose the “best” model? In general, we should
- minimize AIC or BIC,
- principle of parsimony, and
- maximize prediction ability – there’s many criteria available, such as
MAPE(mean absolute percentage error).
The MAPE is given by
$$ MAPE = \frac{1}{T^} \sum_{l=1}^{T^}\left| \frac{X_{t+l} - X_t(l)}{X_{t+l}} \right| $$
where $T^*$ is the length of the training time series. The MAPE is a measure of prediction accuracy of our forecasting model. It has a very intuitive interpretation in terms of relative error.
To calculate the MAPE, we need to split our series into two parts: one for training and one for testing. Instead of a random split as often seen in machine learning methods, we cut our series at some point and use the remaining data for testing3.
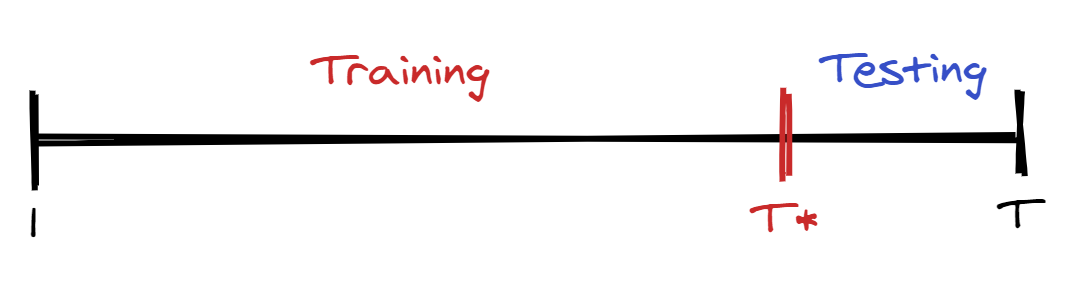
Let’s try this in R on the Lake Huron dataset. We’re going to fit four different models, starting from the AR(2) model:
| |
If we examine the diagnosis plots, there seems to be a spike at lag 9 for the residuals:
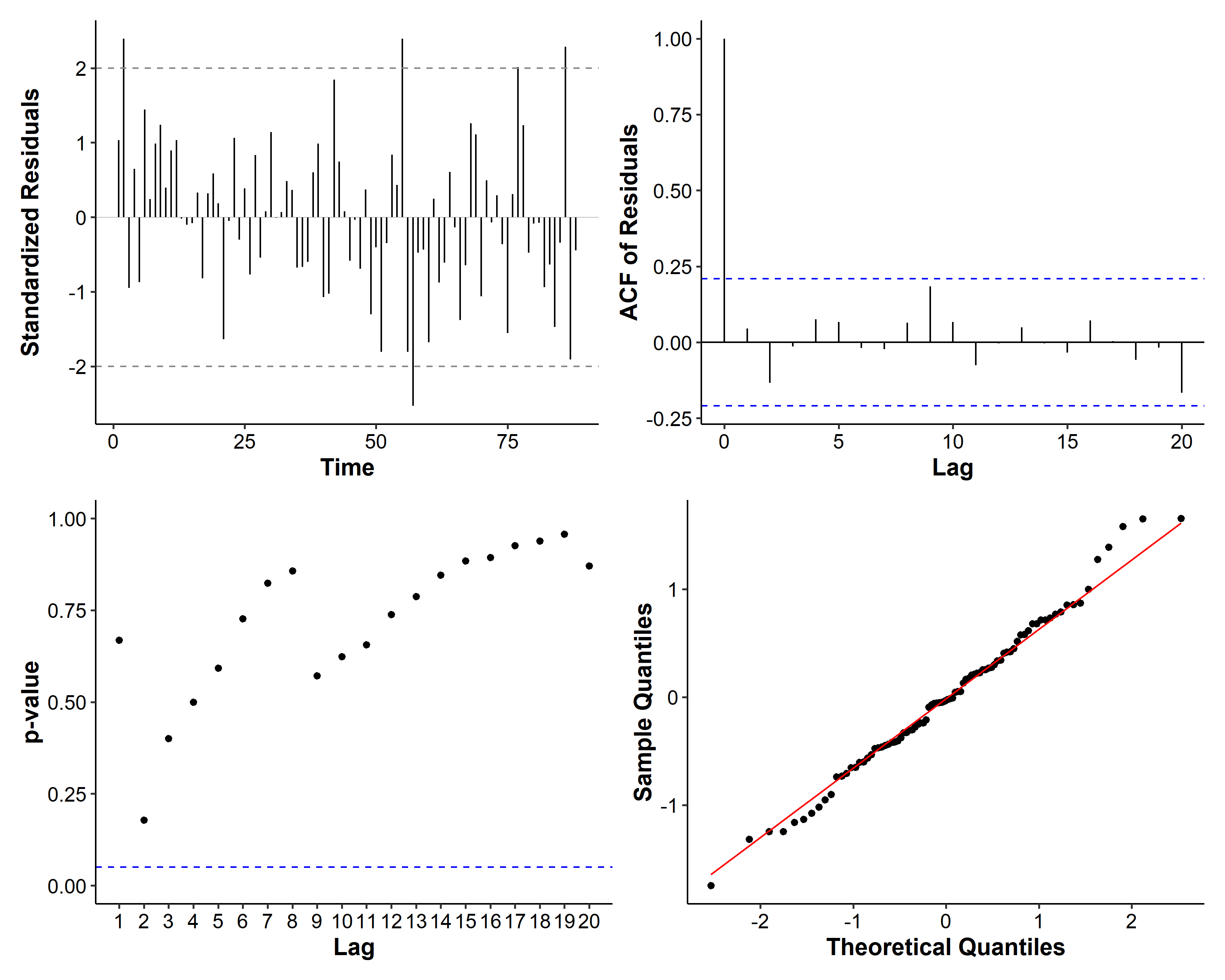
So we also consider the following models:
$$ \begin{gathered} (1 - \phi_1 B - \phi_2 B^2 - \phi_9 B^9)X_t = Z_t \\ (1 - \phi_1 B - \phi_2 B^2)X_t = (1 + \theta_9 B^9)Z_t \\ (1 - -\phi_1 B)X_t = (1 + \theta_1 B)Z_t \end{gathered} $$
where ARMA(1, 1) is considered because it’s a competing model with AR(2).
| |
Here only the NAs in the fixed parameter will be varied. We should also check the diagnosis plots for each model, but the figures are omitted for the sake of brevity. To calculate the BIC, we can use the BIC() function on the model objects. To calculate the MAPE, the following snippet can be used:
| |
We summarize our results in the table below. The rank of each model is given in bold for each criterion. Overall ARMA(1, 1) seems like the best model as it ranks first or second in most cases, and is a simpler model than MA(9).
| Criteria | AR(2) | AR(9) | MA(9) | ARMA(1, 1) |
|---|---|---|---|---|
| AIC | 193.8007 (4) | 193.6452 (3) | 190.973 (1) | 191.9973 (2) |
| BIC | 203.7101 (3) | 206.0319 (4) | 203.3597 (2) | 201.9066 (1) |
| # parameters | 3 (1) | 4 (3) | 4 (3) | 3 (1) |
| MAPE | 0.001737 (2) | 0.001964 (4) | 0.001711 (1) | 0.001815 (3) |
After we’ve decided which model to use, we should go back and use the entire dataset including the testing data. The final model is
$$ (1 - 0.7449B)(X_t - 579.0555) = (1 + 0.3206B)Z_t, \quad \hat\sigma^2 = 0.4749 $$
| Nov 17 | Spectral Analysis | 9 min read |
| Nov 02 | Decomposition and Smoothing Methods | 14 min read |
| Oct 13 | Seasonal Time Series | 17 min read |
| Oct 09 | Variability of Nonstationary Time Series | 13 min read |
| Oct 05 | ARIMA Models | 9 min read |