ARIMA Models

Previously we introduced ARMA models that combined the power of autoregressive series and moving average models. Recall that when modeling a series using the arima function, the order parameter had three integer components $(p, d, q)$ and we always set $d=0$. The three integers are the AR order, the degree of differencing, and the MA order.
Definition
The Autoregressive Integrated Moving Average (ARIMA) model uses an ARMA model after the $d^{th}$ order differencing. $X_t: ARIMA(p, d, q)$ can be expressed as $(1-B)^d X_t: ARMA(p, q)$, or
$$ \Phi(B)(1-B)^d X_t = \Theta(B)Z_t, $$
where
$$ \begin{gathered} \Phi(B) = 1 - \phi_1 B - \phi_2 B^2 - \cdots - \phi_p B^p \\ \Theta(B) = 1 + \theta_1 B + \theta_2 B^2 + \cdots + \theta_q B^q \end{gathered} $$
For example, an ARIMA(2, 1, 0) model is given by
$$ (1 - \phi_1 B - \phi_2 B^2)(1-B)X_t = Z_t $$
An ARIMA(1, 1, 2) model is given by
$$ (1 - \phi B)(1-B) X_t = (1 + \theta_1 B + \theta_2 B^2)Z_t $$
And an ARIMA(0, 2, 1) model:
$$ (1-B)^2 X_t = (1 + \theta B)Z_t $$
Finding the order
We’ll explain how to find the order of ARIMA models through some exercises. After this section we should be able to identify $p$, $d$ and $q$ when looking at a written model.
Unlike the ARMA model, it’s not easy to recognize the three orders together. To find the order of an ARIMA model, we need to convert the models to the canonical format and first determine $d$.
$X_t = X_{t-1} + Z_t + 0.2 Z_{t-1} - 0.5 Z_{t-2}$.
$$ \begin{gathered} X_t - X_{t-1} = Z_t + 0.2 Z_{t-1} - 0.5 Z_{t-2} \\ (1-B)X_t = (1 + 0.2 B - 0.5B^2)Z_t \end{gathered} $$
This is an ARIMA(0, 1, 2) model. The $(1-B)$ part should be considered as differencing and not AR(1).
$X_t = 1.7 X_{t-1} - 0.7 X_{t-2} + Z_t + 0.4 Z_{t-1}$.
$$ \begin{gathered} X_t - 1.7 X_{t-1} + 0.7 X_{t-2} = Z_t + 0.4 Z_{t-1} \\ (1 - 1.7 B + 0.7 B^2)X_t = (1 + 0.4 B)Z_t \end{gathered} $$
We can easily see the MA(1) order from the RHS. For the LHS, note that it contains a differencing term:
$$ (1-0.7B)(1-B)X_t = (1 + 0.4B)Z_t $$
So it’s not an ARMA(2, 1) model, but actually an ARIMA(1, 1, 1) model. Generally we check if $B=1$ is a root for the polynomial on the LHS.
$X_t = 1.6 X_{t-1} - 0.5 X_{t-2} - 0.1 X_{t-3} + Z_t$.
$$ (1 - 1.6B + 0.5 B^2 + 0.1 B^3)X_t = Z_t $$
There’s no MA part. $B=1$ is a solution for the LHS, so
$$ (1 - 0.6B - 0.1 B^2)(1-B)X_t = Z_t $$
$B=1$ is no longer a solution for $(1 - 0.6B - 0.1 B^2)$, so our model is ARIMA(2, 1, 0).
Simulated ARIMA series
In this section we’re going to simulate some ARIMA series with different parameters, and see if we can determine $d$ and then $p$ and $q$ from the ACF and PACF.
IMA(1, 1)
This is the same as an ARIMA(0, 1, 1) model and there’s no AR part. Our model is
$$ (1-B)X_t = (1 - 0.5B)Z_t $$
| |
Plotting the time series, ACF and PACF1, we can see that there’s a clear increasing trend and the ACF slowly decreases, both indicating that differencing is needed. There are three possibilities for the slowly decreasing ACF:
- a mean trend needs to be removed,
- random walk, and
- a stationary process with very strong autocorrelation –
long-range dependence(LRD) time series2. In this case the PACF is also going to slowly decrease.
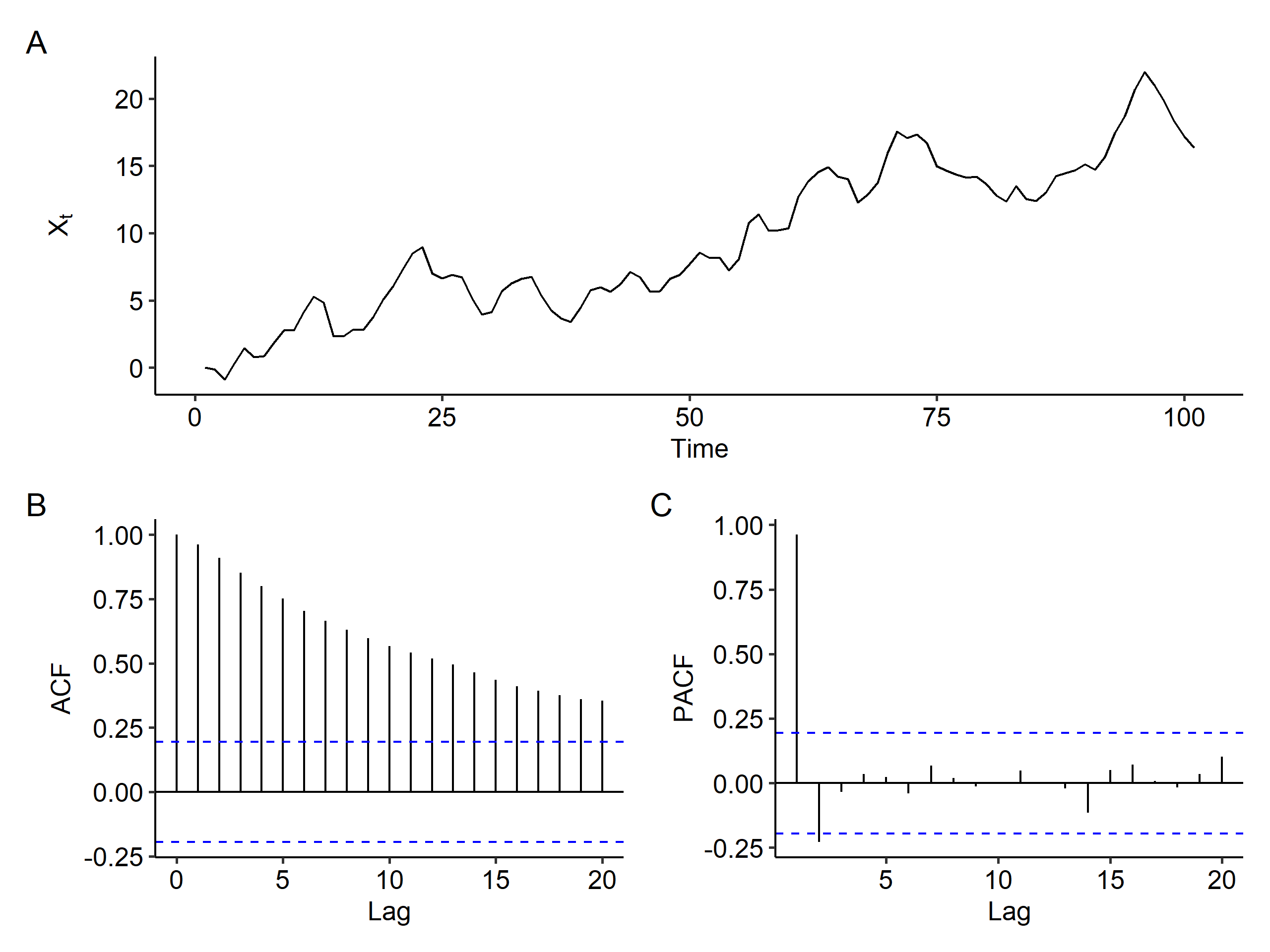
Now if we apply first order differencing, the increasing trend goes away. We see a spike at lag 1 in the ACF plot, and the PACF shows a tail-off pattern, so MA(1) is a good model3. A good candidate for the original series is ARIMA(0, 1, 1), which is our data generating process.
| |
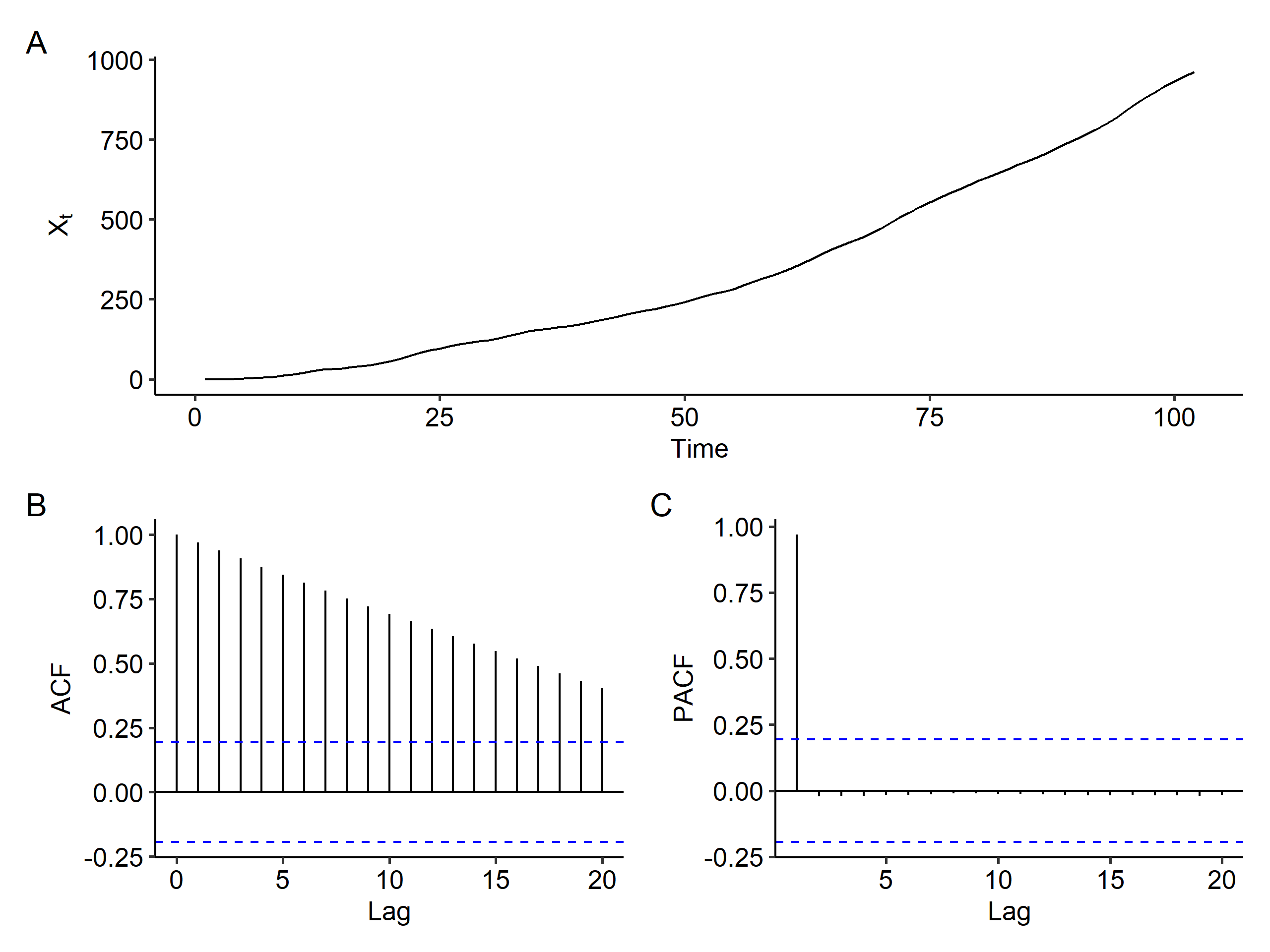
IMA(2, 2)
Our ARIMA(0, 2, 2) model is
$$ (1-B)^2 X_t = (1 + B - 0.6B^2)Z_t $$
| |
Once again, there’s a clear increasing trend and the ACF slowly decreases. We definitely need differencing, but it’s hard to say the order of the differencing.
| |
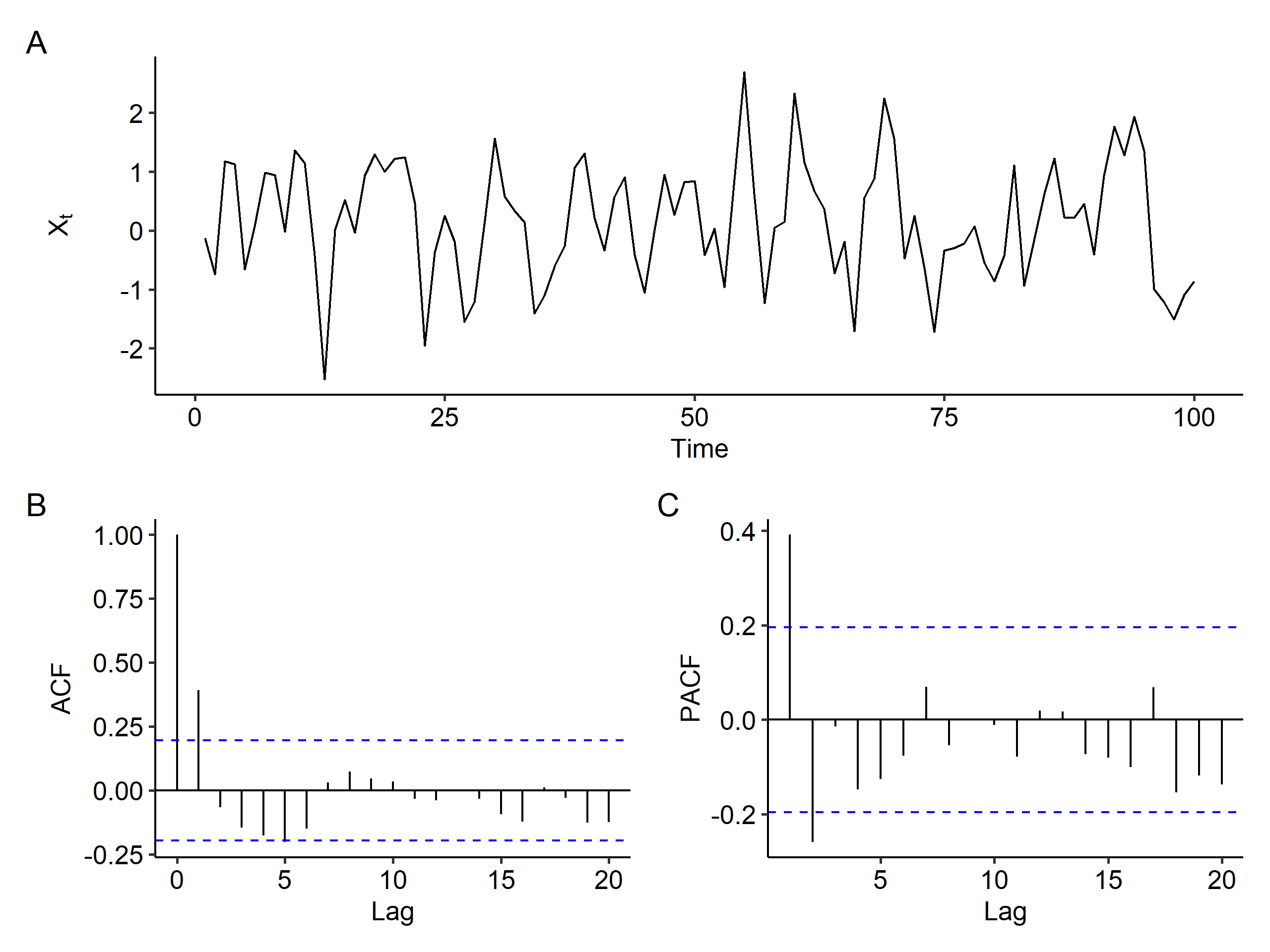
After first order differencing, there’s still a trend in the time series plot, and the ACF still slowly decreases, although faster than before differencing. This suggests that maybe first order differencing was sufficient to remove the mean trend.
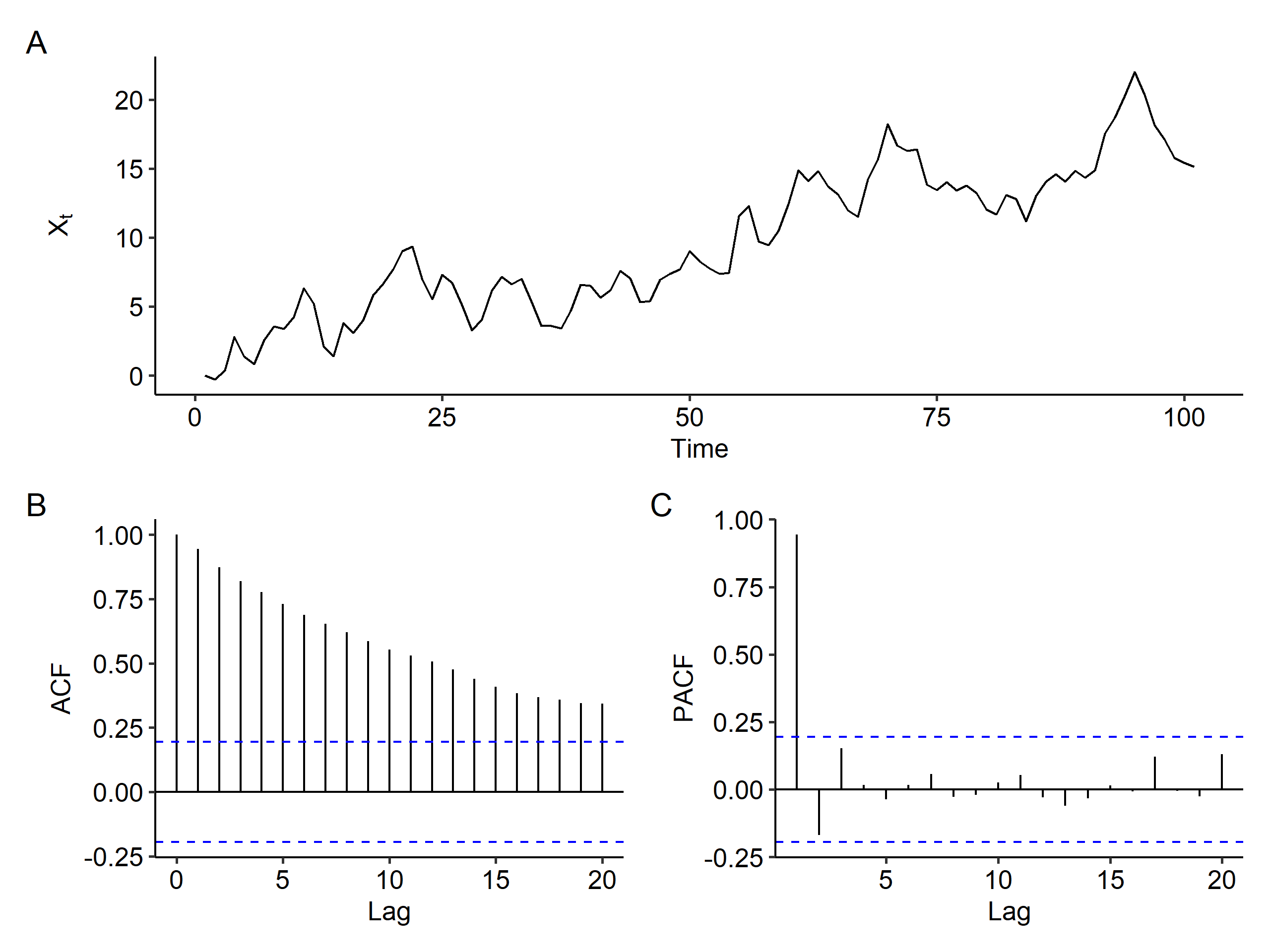
After second order differencing, however, we end up with a stationary process and the slowly decreasing pattern in the ACF is gone.
| |
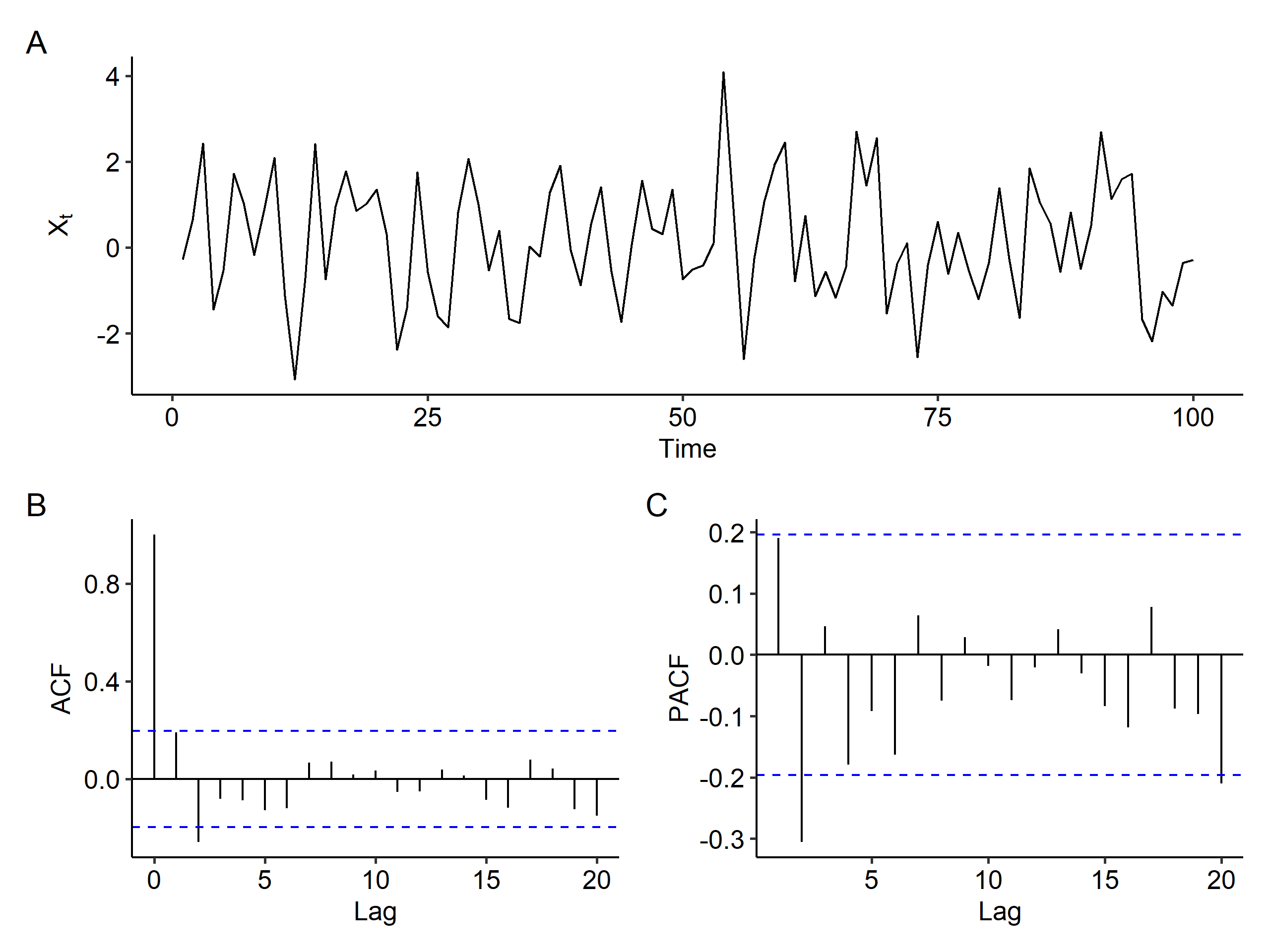
So what’s the order of the model? After second order differencing, we can observe a spike at lag 2 in the ACF plot, and so does the PACF plot. It’s much harder to determine the order compared to the previous case, but an ARIMA(0, 2, 2) model might be suitable.
ARI(1, 1)
This time our model is
$$ (1 - 0.7B)(1-B)X_t = Z_t $$
Following the same process as above, we observe similar patterns in the original series, and the increasing trend is removed after the first order differencing. The ACF of the differenced series tails off, and the PACF is cut off after lag 1, suggesting an AR(1) model.
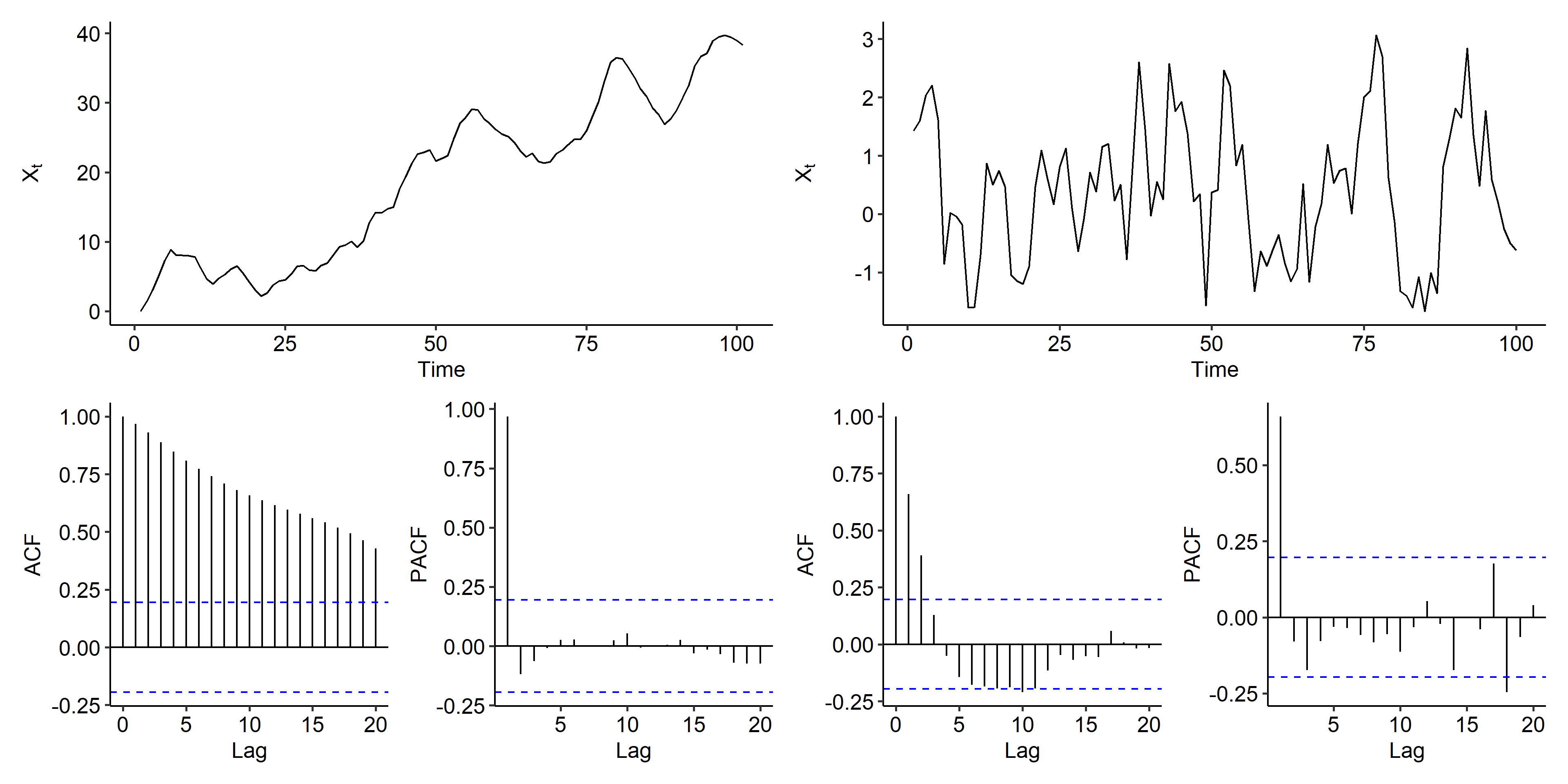
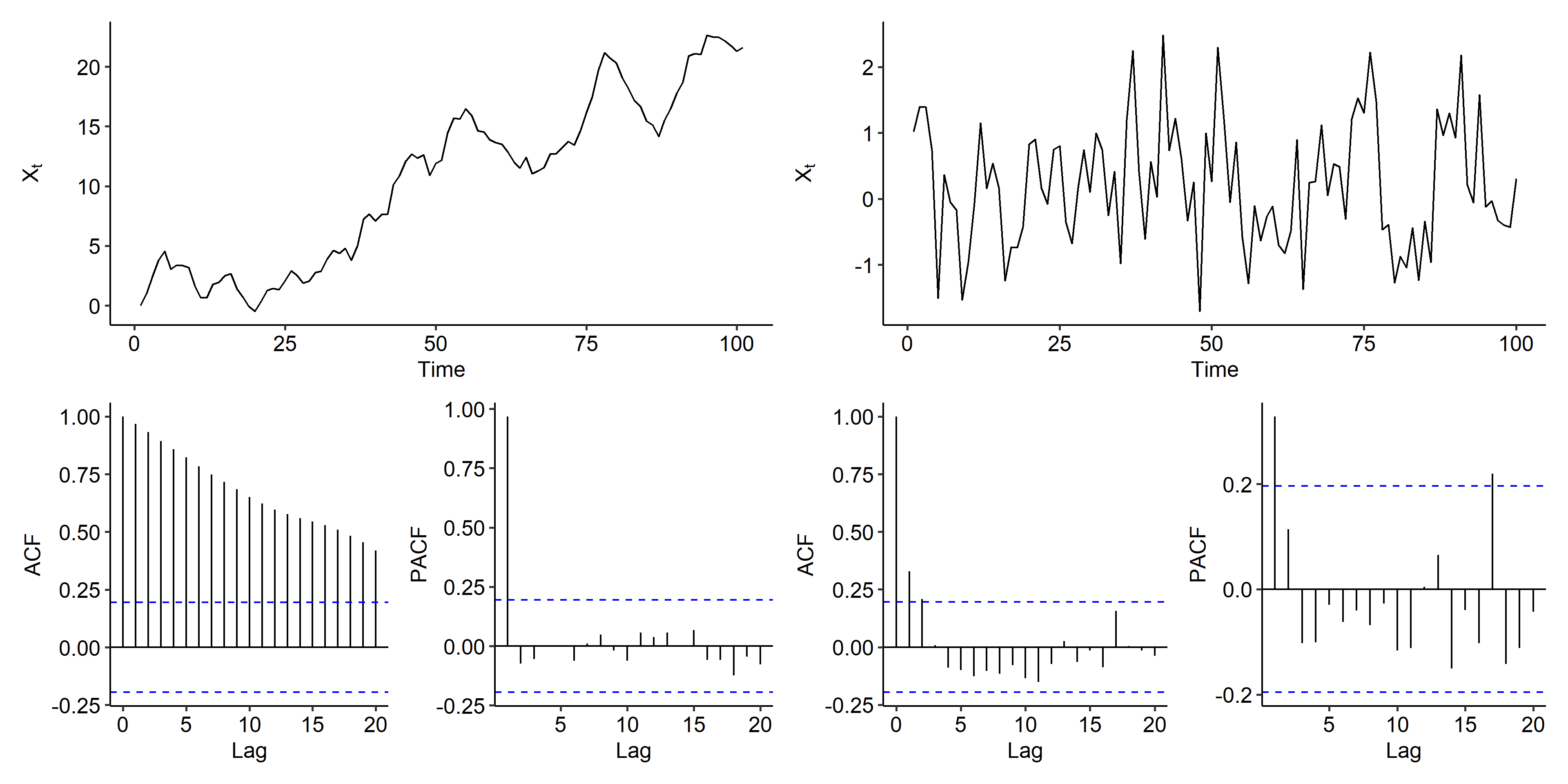
ARIMA(1, 1, 1)
Our final example is the following:
$$ (1 - 0.7B)(1-B)X_t = (1 - 0.4B)Z_t $$
The mean is stabilized after first order differencing, and both and ACF and PACF can be viewed as tail off patterns. Both ARIMA(1, 1, 1) and ARIMA(1, 1, 0) could be considered.
Estimation, diagnosis and forecasting
The procedure is exactly the same as before, except that we include a step of differencing now.
Estimation and diagnosis
Using the ARIMA(1, 1, 1) series as an example:
| |
The fitted model is
$$ (1 - 0.5616B)(1-B)X_t = (1 - 0.2256B)Z_t, \quad Z_t \sim N(0, 6.996) $$
We can also perform differencing manually, and fit an ARMA model for the differenced series:
| |
We can also use the tsdiag() function to view diagnosis plots of the residuals of our model. In this case most of the standardized residuals fall within the $\pm 2$ band, the ACF of the residuals showed no spikes, and all the p-values for the Ljung-Box test were high, suggesting no violation of the model assumptions.
Prediction
To forecast future values, note that we have
$$ \begin{gathered} (1 - \phi B)(1-B)X_t = (1 + \theta B)Z_t \\ (1 - \phi B)(X_t - X_{t-1}) = Z_t + \theta Z_{t-1} \\ X_t - X_{t-1} - \phi X_{t-1} + \phi X_{t-2} = Z_t + \theta Z_{t-1} \\ X_t = X_{t-1} + \phi X_{t-1} - \phi X_{t-2} + Z_t + \theta Z_{t-1} \end{gathered} $$
This is an easier form to find the forecasts.
$$ \begin{aligned} X_t &= (1 + \phi)X_{t-1} - \phi X_{t-2} + Z_t + \theta Z_{t-1} \\ X_t(1) &= E(X_{t+1} \mid X_t, X_{t-1}, \cdots, X_1) \\ &= E((1 + \phi)X_t - \phi X_{t-1} + Z_{t+1} + \theta Z_t \mid X_t, X_{t-1}, \cdots, X_1) \\ &= (1+\phi)X_t - \phi X_{t-1} + E(Z_{t+1}) + \theta Z_t \\ &= (1+\phi)X_t - \phi X_{t-1} + \theta Z_t \end{aligned} $$
Similarly we can find lag 2 and lag $k$ forecasts:
$$ \begin{gathered} X_t(2) = (1 + \phi)X_t(1) - \phi X_t \\ X_t(k) = (1 + \phi)X_t(k-1) - \phi X_t(k-2), k = 3, 4, \cdots \end{gathered} $$
The forecasting error and variance:
$$ \begin{gathered} e_t(1) = X_{t+1} - X_t(1) = Z_{t+1} \\ Var(e_t(1)) = \sigma^2 \end{gathered} $$
Thus, the $100(1-\alpha)\%$ prediction interval for $X_t(1)$ is
$$ (1 + \hat\phi)X_t - \hat\phi X_{t-1} + \hat\theta Z_t \pm z_\frac{\alpha}{2} \cdot \hat\sigma $$
In R, the same predict() function applies. For example,
| |
Notice that although we generated $n=100$ values, the prediction starts from $102$. Also if we ran length(x) we’d get $101$ instead of $100$. This is because we lose one time point after differencing, and the arima.sim() function considers that and simulates one extra value.
The following R code is used to generate the time series plots.
↩︎1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34library(tidyverse) library(patchwork) theme_set(ggpubr::theme_pubr()) plot_acf <- function(object, acf.type = "ACF") { ci <- qnorm((1 + 0.95) / 2) / sqrt(object$n.used) # 95% CI data.frame( Lag = as.numeric(object$lag), ACF = as.numeric(object$acf) ) %>% ggplot(aes(x = Lag, y = ACF)) + geom_segment(aes(x = Lag, xend = Lag, y = 0, yend = ACF)) + geom_hline(yintercept = 0) + geom_hline(yintercept = c(-ci, ci), linetype = "dashed", color = "blue") + ylab(acf.type) } plot_time_series <- function(x, x_type = "WN", lag.max = NULL) { x_acf <- acf(x, lag.max = lag.max, plot = F) x_pacf <- pacf(x, lag.max = lag.max, plot = F) p1 <- tibble(Timepoint = seq(length(x)), x = x) %>% ggplot(aes(Timepoint, x)) + geom_line() + xlab("Time") + ylab(expression(X[t])) p2 <- plot_acf(x_acf, "ACF") p3 <- plot_acf(x_pacf, "PACF") p1 / (p2 | p3) + plot_annotation(tag_levels = 'A') }These are hard to handle, but not frequently seen in time series. ↩︎
In a later chapter we’ll learn the criteria for choosing the best model. ↩︎
| Nov 17 | Spectral Analysis | 9 min read |
| Nov 02 | Decomposition and Smoothing Methods | 14 min read |
| Oct 13 | Seasonal Time Series | 17 min read |
| Oct 09 | Variability of Nonstationary Time Series | 13 min read |
| Sep 30 | Mean Trend | 13 min read |