Bayesian Inference for the Poisson Model

In this lecture we will talk about Bayesian inference for a different model. We will go through the procedure in the same fashion as we did for the binomial model. The key idea is to apply Bayesian inference to other types of data – not all the data we observe are going to be binomial.
We will be using the Fatal flight accidents example in this lecture. The data is adapted from Gelman et al., page 59. The number of fatal accidents on scheduled airline flights worldwide per year over a ten-year period are summarized in the following table:
| Year | Fatal accidents | Year | Fatal accidents |
|---|---|---|---|
| 1976 | 24 | 1981 | 21 |
| 1977 | 25 | 1982 | 26 |
| 1978 | 31 | 1983 | 20 |
| 1979 | 31 | 1984 | 16 |
| 1980 | 22 | 1985 | 22 |
Our goals are to estimate (1) the expected number of fatal accidents in a year, and (2) to estimate the probability of more than 30 fatal accidents occurring in a single year.
Bayesian modeling strategy
Let $y$ be our data, and $\theta$ be the unknown parameter of interest. Recall that we need to specify the sampling model $p(y \mid \theta)$, the prior model $p(\theta)$, and find the posterior distribution $p(\theta \mid y)$ through Bayes’ Theorem. Note that we have a different type of data here. Each observation is a separate count.
Sampling model
Let $Y$ be a random variable counting the number of events occurring within some time interval. The Poisson model is one appropriate choice for this setting:
where the parameter of interest, $\theta$, is the expected number of events occurring within the interval. The probability mass function for the Poisson distribution1 is
The mean and variance of the Poisson distribution are both $\theta$. This means data with a larger mean are also assumed to be more “spread-out”.
Different model
Our data actually consists of $n=10$ observations, each representing the number of fatal accidents in a specific year. How do we account for this? One idea is to assume that each observation is conditionally independent, given $\theta$:
This means
So what is the rationale behind this assumption? Our data are correlated (generally between 20 and 30). However, if we know the mean value $\theta$, then our data appear roughly independent of each other. All we know is that the counts oscillates around the mean value, but we don’t necessarily know anything else about the next value given the previous one.
Why not binomial
The other question we want to address is that why don’t we use the binomial model instead of the Poisson model? The binomial model is also counting things (# of successes in trials). This is because
- We don’t have any data that shows the total number of scheduled flights worldwide. We don’t know the sample size, other than the fact that it is probably a very large number.
- Probabilities of fatal accidents are very small (close to 0 as we would hope).
- Events, i.e. fatal airline accidents, occur continuously over time, and it makes sense to think about time between events.
That being said, we would probably get similar results if we knew what the sample size was. In fact, the Poisson distribution approximates the binomial distribution for large sample size $n$ and small success probability $p$.
Prior model
With the sampling model determined, now we need to specify a prior model for the parameter $\theta$. All we know is that $\theta > 0$. One suitable choice is the gamma distribution2 $\theta \sim Gamma(a, b)$, which has probability density function:
where $\Gamma(a)$ is the gamma function that’s defined in the same way as in the beta distribution. Note that there are several ways to formulate the gamma distribution. In this formulation, $a$ is the “shape” parameter, and $b$ is the “rate” parameter. In R we can use either the rate parameter or the scale parameter, where scale is just the reciprocal of rate.
Some properties of the gamma distribution:
We’ll soon see why this is chosen as the prior model.
Computing the posterior
We can now find the posterior using Bayes’ Theorem with proportionality statements:
The last term is the kernel of $Gamma\left( a + \sum_{i=1}^n y_i, b+n \right)$, so the posterior distribution is
We started with a gamma prior and got a gamma posterior. The gamma distribution is the conjugate prior for the Poisson sampling model.
Selecting prior hyperparameters
Hyperparameters are the parameters of our prior distribution. Under a $Gamma(a, b)$ prior, we must select $a$ and $b$ ahead of time. Some common choices in the presence of information are:
This is called the prior sample size approach. For our example, suppose we had counts from the previous 10 years. We could say $b=10$ and $a$ is the sum of observations in these 10 years.
An alternative when the prior information is not specified is to make a guess for the prior mean to be $m$, and the prior variance to be $s^2$. We then set
and solve this system of two equations for $a$ and $b$. This is the prior mean/variance approach.
What if we have no knowledge about the previous history of fatal airline accidents? How could we choose $a$ and $b$ with a lack of prior information? We can’t set $a=b=1$ like we did with the beta distribution, because $\theta$ can be any positive value in the gamma distribution, and there’s no uniform distribution from zero to infinity.
The form of the posterior $\eqref{eq:gamma-posterior}$ suggests setting $a$ and $b$ close to 0 (but not equal to 0) will lead to the data dominating posterior inference. As we can see in the figure below3, there’s very little difference in the posteriors when $a=b=0.1$ and $a=b=0.01$.
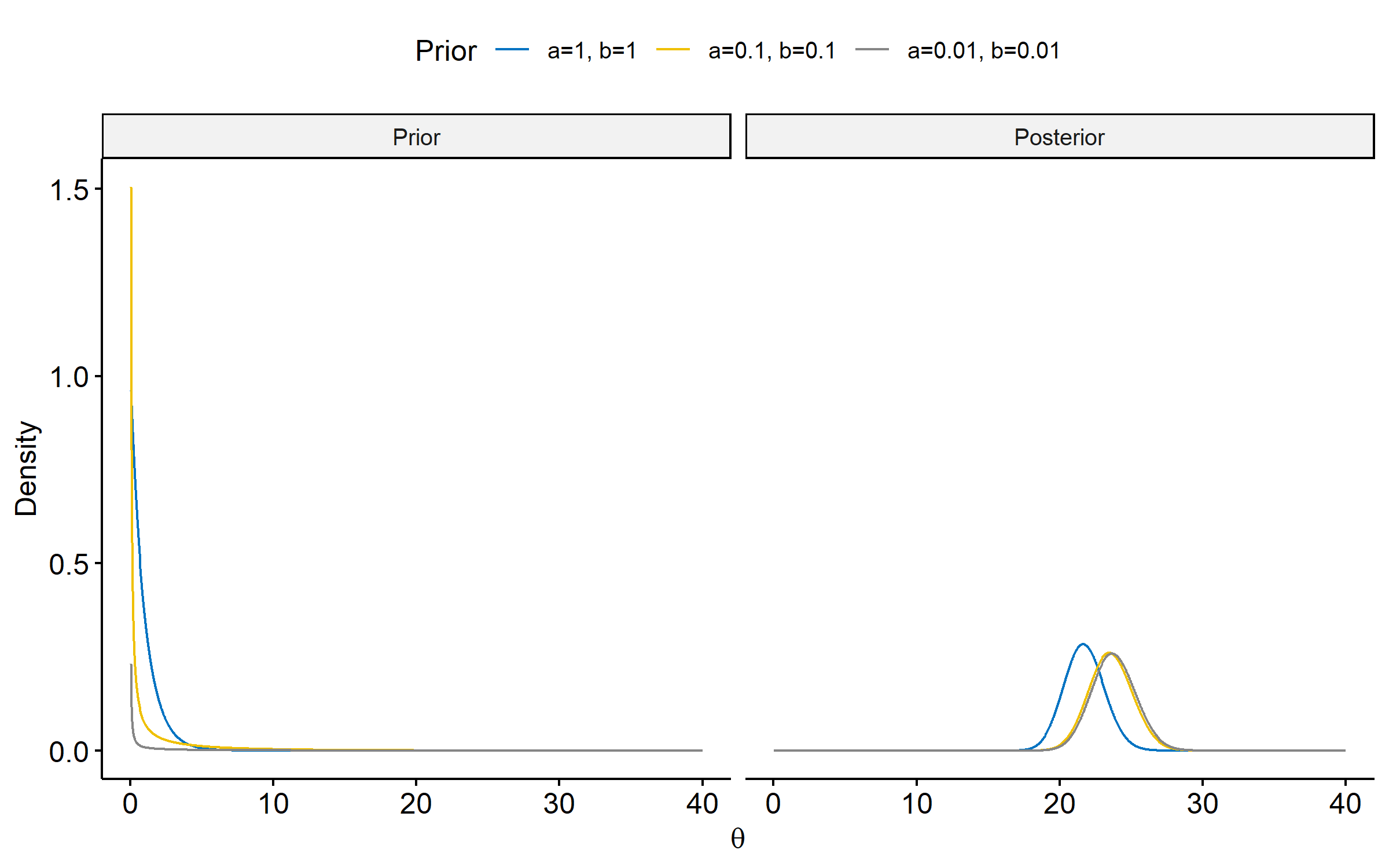
Posterior summaries
To see which one of the priors is the most adequate, we can examine the posterior summaries. The posterior mean can be written as:
Here we have a weighted average of the prior mean and the sample mean. As $n \rightarrow \infty$, $\frac{b}{b+n} \rightarrow 1$ and the posterior mean approaches the sample mean $\bar{y}$. Just like the binomial case, when we have a large sample size, the data overrides the prior.
The formulas for the MAP estimate is
And for the posterior variance:
For the three posteriors we obtained above, the posterior summaries are given as follows.
| Posterior | $a=b=1$ | $a=b=0.1$ | $a=b=0.01$ |
|---|---|---|---|
| Posterior mean | 21.73 | 23.57 | 23.78 |
| MAP | 21.64 | 23.48 | 23.68 |
| Posterior variance | 1.98 | 2.33 | 2.38 |
| 95% HPD CI | (19.00, 24.50) | (20.61, 26.59) | (20.79, 26.82) |
Again, the second and third posteriors have very similar summaries.
Computing posterior probability
Recall that in the original problem, we were interested in estimating the probability of more than 30 expected fatal accidents in a single year. Once we have the posterior of $\theta$, we can compute the following posterior probability:
which is the area under the posterior pdf when $\theta > 30$4. For the three posteriors, the posterior probabilities are $6.05 \times 10^{-8}$, $4.89 \times 10^{-5}$ and $8.77 \times 10^{-5}$, respectively.
For all three priors, we would conclude that there’s virtually zero probability of more than 30 expected fatalities in a given year. If this is our only goal, then using any of the three posteriors is fine. If we are interested in exactly how rare these events are, then using posteriors 2 and 3 might make more sense as we might prefer to over-estimate the posterior probability than to under-estimate it.
A difference here is the Poisson distribution can hypothetically go to infinity, whereas the binomial distribution is capped by the sample size. ↩︎
We can’t use the beta distribution here because it’s defined for $\theta$’s from 0 to 1. ↩︎
The code for plotting Figure 1 is given below.
↩︎1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32library(tidyverse) library(ggpubr) priors <- data.frame(theta = seq(0, 40, length.out = 1000)) %>% filter(theta != 0) %>% mutate( `a=1, b=1` = dgamma(theta, shape = 1, rate = 1), `a=0.1, b=0.1` = dgamma(theta, shape = 0.1, rate = 0.1), `a=0.01, b=0.01` = dgamma(theta, shape = 0.01, rate = 0.01), ) %>% pivot_longer(-theta, names_to = "Prior", values_to = "Density") %>% mutate(Dist = "Prior") posteriors <- data.frame(theta = seq(0, 40, length.out = 1000)) %>% filter(theta != 0) %>% mutate( `a=1, b=1` = dgamma(theta, shape = 1+238, rate = 1+10), `a=0.1, b=0.1` = dgamma(theta, shape = 0.1+238, rate = 0.1+10), `a=0.01, b=0.01` = dgamma(theta, shape = 0.01+238, rate = 0.01+10), ) %>% pivot_longer(-theta, names_to = "Prior", values_to = "Density") %>% mutate(Dist = "Posterior") bind_rows(priors, posteriors) %>% mutate( Prior = fct_inorder(Prior), Dist = fct_inorder(Dist)) %>% ggline(x = "theta", y = "Density", numeric.x.axis = T, plot_type = "l", xlab = expression(theta), palette = "jco", color = "Prior") %>% facet(~Dist, ncol = 2, scales = "free_y")In R, use the
pgamma()function to compute the posterior probabilities. ↩︎
| Apr 26 | A Bayesian Perspective on Missing Data Imputation | 11 min read |
| Apr 19 | Bayesian Generalized Linear Models | 8 min read |
| Apr 12 | Penalized Linear Regression and Model Selection | 18 min read |
| Apr 05 | Bayesian Linear Regression | 18 min read |
| Mar 29 | Hierarchical Models | 18 min read |